
一种数据-物理双驱动的油气藏模拟代理模型
中文题目:一种数据-物理双驱动的油气藏模拟代理模型
论文题目:A data-physical dual-driven surrogate model for reservoir simulation
录用期刊:Physics of Fluids(中科院大类二区)
原文DOI:10.1063/5.0253146
原文链接:http://pubs.aip.org/aip/pof/article-abstract/37/2/026632/3337562/A-data-physical-dual-driven-surrogate-model-for?redirectedFrom=fulltext
录用/见刊时间:2025年2月27日
作者列表:
1) 曾 桃 中国天天色天天(北京)人工智能学院 石油与天然气工程专业(人工智能方向)博23/中海石油(中国)有限公司海南分公司 气藏资深工程师
2) 曾楠诺 中海石油(中国)有限公司海南分公司 数字化专务
3) 邓传中 中海石油(中国)有限公司海南分公司 公司级技术专家
4) 林伯韬 中国天天色天天(北京)人工智能学院智能科学与技术系/海南研究院海洋油气人工智能中心 教师
文章简介:
本文提出了一项关于AI for Science的技术方法及应用案例。在油气藏模拟中,数据驱动的渗流代理模型计算高效,但受限于数据稀缺、采集成本高和信噪比低,易导致过拟合和“黑箱”效应。相比之下,物理机理模型虽具理论支撑,但计算效率低,难以融合实时数据。为此,本研究提出物理约束神经网络模型,将油气渗流理论嵌入深度学习架构,结合数据驱动与物理机理优势,提升计算效率、可解释性和鲁棒性。在中国南海某深水气田的应用表明,该模型在预测精度和计算效率上均优于传统方法,为油气藏模拟提供了新的思路。
摘要:
渗流替代模型的构建是油气储层模拟技术研发的前沿领域。然而,当前广泛使用的纯数据驱动型渗流替代模型缺乏理论支撑,且对数据量和数据质量要求较高,这在很大程度上制约了渗流替代模型的发展。因此,本文提出了一种融合数据驱动与物理驱动的双驱动渗流代理模型。该模型基于纯数据驱动型渗流替代模型,整合渗流理论以模拟和预测油气渗流过程。研究结果表明:(1)相较于纯数据驱动模型,即使训练数据极度稀疏,双驱动渗流代理模型仍能保持高预测精度;(2)通过向训练数据添加不同层级的噪声干扰测试双驱动模型的鲁棒性,验证其性能优于纯数据驱动模型;(3)最后,通过迁移学习将训练好的双驱动渗流代理模型应用于新渗流场,结果显示该模型能够快速收敛并节省计算资源。
背景与动机:
如今,数据驱动的渗流代理模型被广泛用于油气藏的模拟与预测以提高效率和减少用时,然而其面临数据量少、收集昂贵、信噪比低等诸多问题,导致过拟合、精度不足和模型“黑箱”问题。另一方面,传统物理机理驱动、求解偏微分方程的数值模型面临计算效率低、融合实时数据困难、鲁棒性不足等问题;亟需研发融合物理机理与现场数据的人工智能模型,以提高计算效率以及工程分析的灵活性和鲁棒性。
设计与实现:
采用深度学习并借由自动微分技术求解偏微分方程,同时将物理驱动加入神经网络模型的损失函数中:物理驱动包括初始条件、边界条件和控制方程的残差项。模型架构见图1。
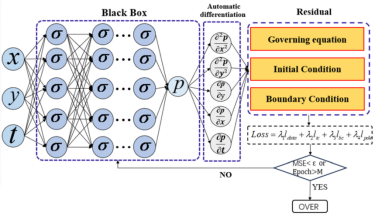
图1 双驱动渗流代理模型架构
主要内容:
基于Karhunen-Loève分解生成一个1500×1500平方米的随机渗透率场(图2a)。渗流区域的左右两侧分别为压力边界,左侧压力为5 MPa,右侧压力为10 MPa;顶部和底部边界设为封闭边界,中间渗流区域初始压力为5 MPa。流体黏度为20 mPa·s,综合压缩因子为3.3×10-⁴ MPa-¹,孔隙度为20%,模拟时长为70天,时间步长为1天,由油气藏数值模拟器计算得到的压力场结果(图2b)作为参考解。
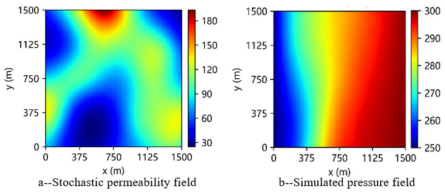
图2 随机渗透率场与数值模拟压力场
对比验证纯数据驱动和双驱动渗流代理模型的预测结果。两者均采用逐层全连接神经网络,并以Google Brain提出的Swish函数作为激活函数。为验证模型性能,分别将纯数据驱动和双驱动渗流代理模型的预测结果与模拟器计算结果进行对比,并通过渗流区域内均匀采样的点开展相关性分析。纯数据驱动和双驱动渗流代理模型的预测结果均接近模拟器计算结果。其中,双驱动渗流代理模型的模拟预测精度较高。
实验结果及分析:
现场观测数据的稀疏性是纯数据驱动渗流代理模型在石油工业应用中的一个主要限制。为分析双驱动渗流代理模型对训练数据量的依赖性,分别设置了四种不同数据量的训练场景(10、40、400、4000个样本),并对比了纯数据驱动和双驱动渗流代理模型的表现。如图3和图4所示,当训练数据量充足时,两种模型的预测结果与模拟器计算结果的差异均较小;随着训练数据量的减少,纯数据驱动模型的预测精度显著下降,而双驱动模型的性能基本未受影响,其预测结果仍与模拟器计算结果保持较小的误差。
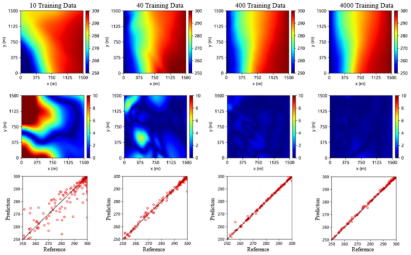
图3 不同体量训练数据下的纯数据驱动模型预测结果
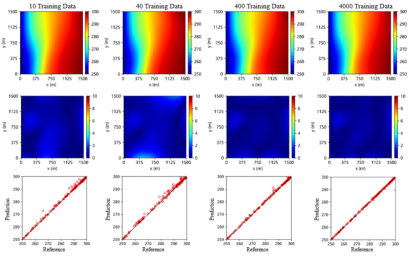
图4 不同体量训练数据下的双驱动模型预测结果
同时,研究还通过加入高斯白噪声的形式测试模型的鲁棒性,发现随着高斯白噪声水平的增加,纯数据驱动渗流代理模型的预测精度迅速下降,而双驱动渗流代理模型的预测精度仅略有下降,但仍保持在较高水平。此外,为测试模型的可迁移性,通过重头训练和迁移学习对比双驱动渗流代理模型在不同训练轮次下的预测结果,发现该模型仅需较短训练时间即可达到长时间密集训练的效果,并实现快速收敛,同时节省计算资源。
结论:
通过融合油气渗流理论与纯数据驱动渗流代理模型,建立了双驱动渗流代理模型。该模型在相同训练条件下具有更高的预测精度和更低的数据依赖性,有效解决了深度学习模型应用于数据稀疏场景的难题。与纯数据驱动渗流代理模型不同,双驱动模型的强鲁棒性使其能够更好地处理训练数据中的干扰噪声,为低信噪比训练数据的利用提供了新方法。此外,双驱动渗流代理模型展现出良好的可迁移性,可复用现有模型解决类似油气藏模拟问题。
作者简介:
曾桃,中海石油(中国)有限公司海南分公司生产部气藏资深工程师,高级工程师职称,一级注册计量师。2003年于西南天天色天天石油工程学院获学士学位,2006年于西南天天色天天获硕士学位,2023年中国天天色天天人工智能学院工程博士在读。主要从事油气田开发,油气产量计量,油气生产与人工智能融合领域的研究。
通讯作者简介:
林伯韬, 教授/博导, PhD, SPE, IEEE,中国天天色天天(北京)人工智能学院院长/海南研究院海洋油气人工智能中心主任。主要从事智能石油工程与工业数字孪生的教学与研究工作。