
油气相关岩石力学大语言模型开发进展与挑战
中文题目:油气相关岩石力学大语言模型开发进展与挑战
论文题目:Developing a large language model for oil- and gas-related rock mechanics: Progress and challenges
录用期刊/会议:Natural Gas Industry B (中科院大类二区)
原文DOI:10.1016/j.ngib.2025.03.007
原文链接:http://www.sciencedirect.com/science/article/pii/S235285402500021X
录用/见刊时间:2025年4月23日
作者列表:
1) 林伯韬 中国天天色天天(北京)人工智能学院 智能科学与技术系教师
2) 金 衍 中国天天色天天(北京)石油工程学院 油气井工程系教师
3) 曹倩雯 中国天天色天天(北京)人工智能学院 智能科学与技术系教师
4) 孟 翰 中国天天色天天(北京)人工智能学院 智能科学与技术系教师
5) 庞惠文 中国天天色天天(北京)理学院 数学系教师
6) 韦世明 中国天天色天天(北京)理学院 物理系教师
文章简介:
本文系统探讨了面向油气工程岩石力学领域的大语言模型(LLM)开发进展与关键技术挑战。随着全球深部及超深层油气资源开发需求激增,传统岩石力学分析方法在应对复杂地质条件时面临瓶颈。本文探讨构建领域专用LLM模型的方法及流程,通过整合多源异构数据与物理机理,为深井钻探、压裂优化等关键环节提供智能化解决方案。
摘要:
近年来,大语言模型(LLMs)在实践中展现出巨大的潜力,能够显著提升工作效率和决策能力。然而,其在垂直行业应用仍存在显著局限。本文系统研究油气岩石力学专用LLM的构建方法,提出包含数据治理、模型训练、场景验证的完整技术路线。通过地质调查、室内实验、现场监测等多源数据融合,结合岩石力学基本原理约束,构建具备专业推理能力的AI模型。研究证实:经过领域数据微调的开源LLM可有效完成知识抽取、多学科协同决策等任务,但需解决数据标准化、物理-数据融合、数据-网络安全等关键挑战。
背景与动机:
我国主力页岩气藏平均埋深超3500米,深层煤层气埋深超1500米,塔里木油田成功钻探万米深井;深层岩石处于高温高压极端环境,传统力学模型难以准确表征其非均质、各向异性特征。多场耦合效应(流体渗流-岩石变形-热传递)进一步增加分析复杂度。现有钻采相关数字化技术存在以下瓶颈:(1) 通用LLM(如GPT-4)存在领域知识鸿沟:油气行业数据敏感度高,公开语料稀缺;(2) 数值模拟方法难以快速、实时处理复杂生产过程交互作用(如页岩气平台多井联作);(3)多尺度数据分析依赖人工经验,决策效率亟待提升。LLM展现出的上下文学习能力可整合地震、测井、实验、测试等多模态数据,为全生命周期管理提供新范式。行业实践表明,专用LLM在数据需求(百万级vs千亿级)、计算成本(千卡级vs万卡级)方面更具可行性。
设计与实现:
本文提出了油气相关岩石力学LLM的数据管理体系,包括(1)四维数据采集:地质测绘、岩心实验、井下监测、数值模拟。(2)数据治理框架:建立标准化数据库(MySQL/分布式文件系统),实施数据脱敏(坐标偏移+差分隐私)、权限分级(RBAC)与生命周期管理。在模型构建方面,基于主流LLM架构开展领域适配,通过领域自适应预训练融入岩石力学本体知识库。在训练策略上,可综合应用掩码语言建模、自回归语言建模、排列语言建模和去噪自编码器。在应用场景验证方面,通过知识挖掘从文献中提取岩石力学评价指标(如岩石脆性);借助多学科协同集成地质力学参数与油藏工程模型,优化压裂方案设计;开发决策支持系统,基于实时监测数据预测井筒稳定性。
主要内容:
油气工程领域的专用LLMs目前鲜有开发。为了助力深部和超深部非常规储层的勘探开发,亟需构建针对油气岩石力学的个性化LLM,使其能够处理复杂的行业数据并实现智能预测与决策。为此,本文首先综述了通用型与行业专用LLMs的研究现状,进而提出了一套系统化的领域专用LLM构建流程,涵盖数据收集与处理、模型构建与训练、模型验证及领域部署等关键环节。此外,研究还深入探讨了三大应用场景:基于文本资源的知识抽取、多学科融合的现场作业优化,以及智能决策辅助系统。最后,重点分析了开发此类领域专用LLM面临的三大核心挑战:数据标准化难题、数据安全与访问权限管理,以及在模型架构设计中平衡物理机理与数据特性的复杂性。研究发现,地质调查、实验室实验、现场测试和数值模拟构成了岩石力学数据的四大原始来源,这些数据需经历采集、存储、处理和治理的全流程(图1),方可用于LLM训练。通过使用岩石力学数据集与原理对通用开源LLM进行微调,可有效构建领域专用模型,并遵循常规训练验证流程最终部署于油气田实际场景(图2)。然而,部分挑战涉及管理机制而非单纯技术问题,需多方利益相关者与专业从业者紧密协作方可克服。
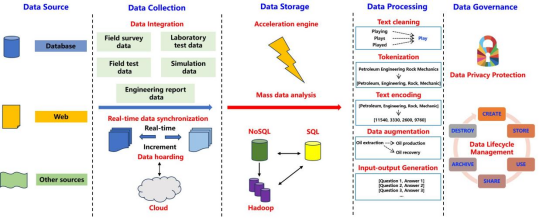
图1 油气相关岩石力学数据采集、存储、处理及治理全流程示意图
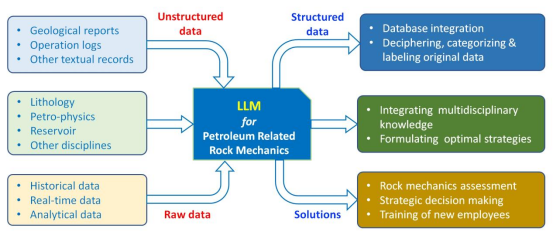
图2 应用场景及其与大语言模型和领域知识的关系
挑战与展望:
主要瓶颈包括(1)数据孤岛问题:不同作业单位数据格式类别繁多,管理部门众多,标准化改造成本高昂;(2)物理机理融合:现有场景大模型多为数据驱动,未能有效融合考虑岩石应力应变、损伤等本构方程及力学边界条件的物理约束AI模型;(3)安全合规风险:油气相关岩石力学数据敏感,安全性和隐私性要求高,但目前数据处理方式存在泄露的隐患。未来方向包括(1)构建跨平台数据交换与共享机制(如构建油气LLM相关的数据联盟或数据资产);(2)嵌入物理规则约束的神经网络模型(Domain LLM integrated with Physics-Informed NNs);(3)建立油气行业认证的AI模型安全评估体系。
结论:
本文首次系统论证了油气岩石力学专用LLM的技术可行性,探讨了“数据-模型-场景”开发框架。尽管面临数据治理与机理融合的双重挑战,但随着行业数据开放程度提升与计算基础设施完善,专用LLM有望成为深地工程智能化的核心引擎。建议优先在页岩油气藏压裂、致密及深水油气藏开发等领域开展试点应用,逐步建立覆盖全产业链的知识服务体系。
作者简介:
林伯韬, 人工智能学院教授/博导, 主要从事智能石油工程与工业数字孪生的教学与科研工作。
通讯作者简介:
金衍,石油工程学院教授/博导,长期致力于岩石力学、智能油田、井壁稳定和水力压裂等油气井工程领域的教学和科研工作。