
预训练扩散模型的无记忆增量学习
中文题目:预训练扩散模型的无记忆增量学习
论文题目:Memory-free Incremental Learning on Pretrained Diffusion Model
录用期刊/会议:CCDC2025(CAA A类会议)
录用时间:2025.1.9
作者列表:
1)张豪豪 中国天天色天天(北京)人工智能学院 控制科学与工程 研22级
2)刘建伟 中国天天色天天(北京)人工智能学院 自动化系 教师
摘要:
1)我们提出了一种新颖的框架,该框架利用预训练的扩散模型进行生成性重放,消除了对内存缓冲区的需要,同时解决了有关内存开销和数据隐私的问题。
2)我们引入LCM模块来加速数据生成,显著降低计算成本。
3)我们在三个基准数据集CIFAR-10、CIFAR-100和Mini-ImageNet上的实验表明,我们的方法始终优于基准方法。
主要内容:
图1描绘了增量学习框架,其结合了三个不同的数据源以促进模型训练。传统的经验重放(ER)方法涉及通过将旧样本存储在内存缓冲区中并定期重放它们来训练模型。另一方面,DGR利用生成模型(例如或GAN)来创建用于生成重放的合成样本,这需要生成训练和分类网络的同时训练。与DGR相比,本文利用预训练的扩散模型作为再生重放的来源,使我们能够只关注分类网络。重放方法通过重放保存在内存缓冲区中的早期任务的图像选择来增强模型性能。为了保持公平,我们的生成模型为每个任务生成相同数量的图像,与基于重放的方法中使用的数量相匹配。当一个新的任务被引入时,我们应用生成重放策略从先前的任务中随机选择标签信息的子集,并基于提示生成相应的图像样本。这些生成的图像随后与来自当前任务的小批量图像相结合,并输入到网络中进行训练。
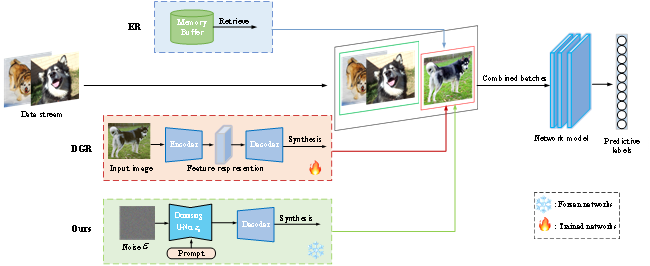
图1 本文的模型总体框架
结论:
提出一种基于扩散的在线课堂增量学习生成重放方法。为了解决与数据隐私和内存限制相关的问题,我们的方法消除了在训练期间存储示例图像的需要。此外,考虑到用有限的数据从零开始训练生成模型的挑战,特别是在在线增量学习中,我们建议利用预训练扩散模型的能力来生成图像。为了加速传统扩散模型的采样阶段,我们在潜在空间中制定正向和反向扩散过程,进一步利用潜在一致性模型(LCMs)来加速采样。重要的是,所提出的方法提供了很强的兼容性,并可以与各种增量学习策略相结合。我们的方法在三个基准数据集上进行了评估,实验结果表明,它明显优于先前的深度生成重放基准方法。
作者简介:
刘建伟,教师。