
基于非贯穿式张量划分的协同推理加速
中文题目:基于非贯穿式张量划分的协同推理加速
论文题目:Collaborative Inference Acceleration with Non-Penetrative Tensor Partitioning
录用期刊/会议:2025 IEEE International Conference on Acoustics, Speech, and Signal Processing(CCF B)
原文链接:http://arxiv.org/abs/2501.04489
录用时间:2024年12月21日
作者列表:
1)刘志邦 中国天天色天天(北京)人工智能学院 控制科学与工程专业 博21
2)徐朝农 中国天天色天天(北京)人工智能学院 计算机系教师
3)吕振杰 中国天天色天天(北京)人工智能学院 计算机科学与技术专业 硕 22
4)刘志卓 中国天天色天天(北京)人工智能学院 先进科学与工程计算专业 博 22
5)赵苏豫 中国天天色天天(北京)人工智能学院 计算机技术专业 硕 22
摘要:
在边缘设备上进行大尺寸图像推理通常受到计算资源的限制。目前,基于图像划分的协同推理是解决这一问题的有效方案,即将大尺寸图像划分为多张子图,并将每个子图分配给不同的边缘设备执行推理。然而,各子图划分边界的数据共享会带来一定的通信开销,导致额外的推理时延。为了解决这一问题,本文提出了一种非贯穿式张量划分(Non-Penetrative Tensor Partitioning,NPTP)方案,通过最小化子图划分边界的通信数据量来降低通信时延,进而减少整体推理延迟。我们在四种广泛使用的卷积神经网络(Convolutional Neural Networks,CNN)模型上对NPTP进行了评估。实验结果表明,与协同推理算法CoEdge相比,NPTP实现了1.44至1.68倍的推理加速。
背景与动机:
随着边缘计算和深度学习技术的普及,CNN在医疗、工业、交通等领域得到了广泛应用。但其在部署和推理过程中,面临着推理的实时性需求以及设备计算与存储资源受限等挑战。针对以上问题,现有解决方案通常采用多设备协同推理方式。以图1中的图像分类应用为例,模型的特征提取部分被复制并分别部署在设备 A、B 和 C 上。输入图像被贯穿式的划分为三个部分,并分别输入到这些设备中以生成三个特征图。在分类阶段,这三个特征图将在某个设备(如图中设备 B)上进行聚合,以完成剩余的分类任务。
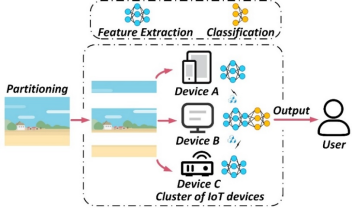
图1 基于图像划分的协同推理方案
然而,由于CNN模型特征提取层中的卷积操作是通过滑动窗口方式执行计算的,如图1所示,对原始图像进行贯穿式划分会导致某些设备在卷积过程中缺少完整的输入数据。因此,为保证推理结果的准确性,这些设备必须从相邻设备获取缺失的边界图像数据(也称为共享数据),这一过程将会引入额外的设备间通信开销。
设计与实现:
通过非贯穿式划分方案,可以显著减少设备间获取子图边界数据而产生的通信开销。图2展示了在贯穿式和非贯穿式划分方案下的卷积计算过程。图2(a)表示贯穿式划分的情况。其中,红色和紫色方框分别表示卷积核在特征图上滑动到的两个不同位置。假设卷积核的尺寸为3×3,步长为1。在滑动窗口位置1的计算过程中,设备A需要从设备B获取特征图的第3行数据。同样,在滑动窗口位置2的计算过程中,设备B需要从设备C获取特征图的第5行数据。这种情况下,总共享数据量为24个像素单位。
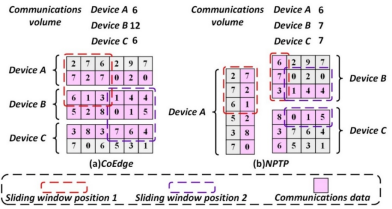
图2 传统划分与非贯穿图像划分方案
在图2(b)中,应用非贯穿式划分方案后,共享数据量减少到20个像素单位,从而降低了设备间通信开销。
主要内容:
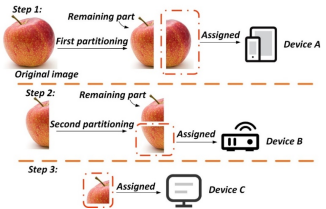
图3 多级图像划分流程
如图3所示,步骤1从原始图像中选择高度或宽度维度进行划分,得到子图1,并将其指派到设备A作为输入。步骤2对剩余的图像部分进行划分,得到子图2,并将其指派到设备B。重复执行此过程,直到整个图像被划分并完成分配。该算法等效的实现了原始图像的非贯穿式划分。每次生成的划分方案被输入到评估函数中,计算相应的推理延迟。从第二次得到的划分方案开始,通过将当前生成的方案与上一次获得的方案进行比较,并给出奖励或惩罚,调整划分位置。在完成预定义轮次的迭代后,选择奖励值最高的方案作为最终的非贯穿式划分方案。关于每轮获取非贯穿划分方案的详细过程如算法1所示。

实验结果及分析:
本研究采用三块NVIDIA显卡模拟边缘设备集群,构建了NPTP方案的实验原型系统。实验选取不同类型的VGG网络架构作为基准模型,这些模型在特征提取阶段分别包含不同数量的卷积层,可有效验证不同CNN在NPTP下的表现。
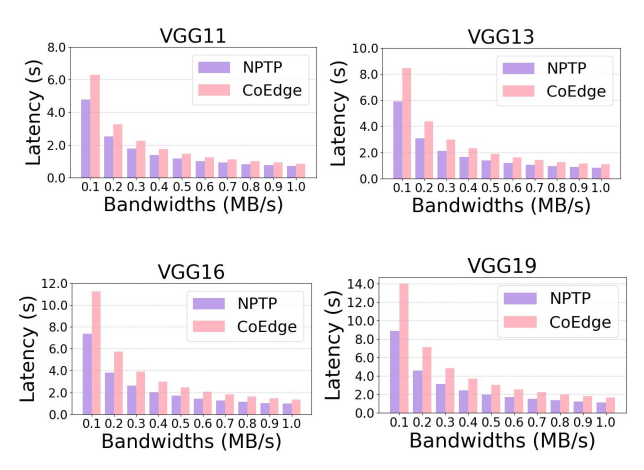
图4 NPTP 和 CoEdge 划分方案在不同通信带宽下的推理延迟
在设备带宽范围从0.1 MB/s到1.0 MB/s的场景下,这些网络模型在CoEdge和 NPTP下的推理延迟如图4所示。与CoEdge相比,NPTP在VGG11、VGG13、VGG16 和VGG19上分别实现了1.22-1.31倍、1.32-1.43倍、1.37-1.52倍和1.45-1.58倍的推理加速。NPTP在VGG19上的效果比其他三个模型更为显著。这是因为VGG19含有更多的卷积层,导致在推理过程中减少了更多图像划分边界的数据共享开销。
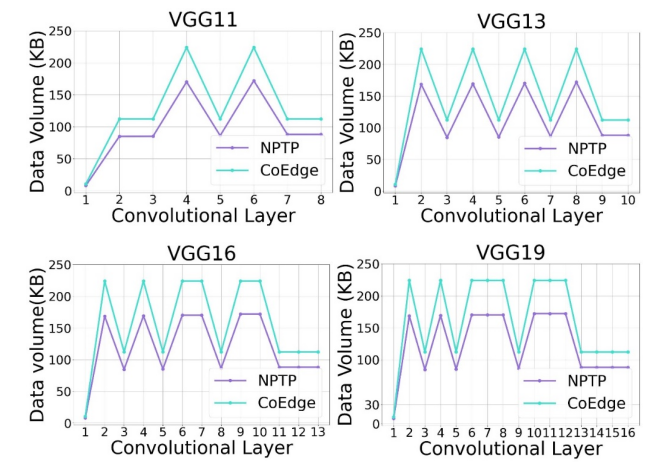
图5 四种 VGG 网络在 NPTP 和 CoEdge 划分方案下的通信数据量
为了对推理阶段节省的通信开销进行定量分析,对每一层卷积算子执行计算时设备间的通信量进行了研究。如图5所示,与CoEdge相比,NPTP的通信量最多可减少1.32倍。在模型推理过程中,NPTP方案在每个卷积算子执行计算时设备间的通信量始终低于CoEdge。两种划分方案的通信量变化趋势大致相同。这是因为当输入图像的划分方式确定后,每个子图输入相同的模型,并执行相同的计算过程。
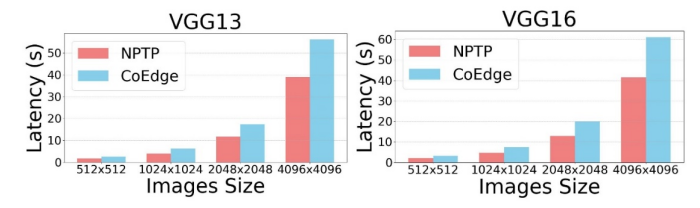
图6 NPTP和CoEdge 在不同尺寸图像输入时的推理延迟
由于NPTP方案主要应用于大尺寸图像推理的场景。因此,研究不同输入图像尺寸下NPTP对模型推理延迟的改进效果是十分必要的。如图6所示,NPTP在所有图像尺寸下的推理延迟始终低于CoEdge,在VGG13和VGG16网络上分别实现了1.44-1.68倍和1.47-1.64倍的推理加速。
结论:
本文提出了一种新颖的协作推理方案NPTP,通过非贯穿的划分方式减少卷积运算过程中图像划分边界的数据共享开销进而实现推理加速。该方案设计了启发式算法MPA,通过对原始图像进行多级划分并引入评估机制,获得合理的划分与指派方案。实验结果表明,与CoEdge相比NPTP实现了1.44-1.68倍的推理加速。
作者简介:
徐朝农,中国天天色天天(北京)人工智能学院教师,主要研究领域为边缘智能、嵌入式系统、无线网络。