
基于多层编码遗传算法的非集输井群生产拉运调度协同优化
中文题目:基于多层编码遗传算法的非集输井群生产拉运调度协同优化
论文题目:Transportation and production collaborative scheduling optimization with multi-layer coding genetic algorithm for non-pipelined wells
录用期刊/会议:Heliyon(中科院大类3区)
原文DOI:[10.1016/j.heliyon.2024.e41307]
原文链接:http://doi.org/10.1016/j.heliyon.2024.e41307
录用/见刊时间:2024-12-26
作者列表:
1)李秋实 中国石油长庆油田公司 高级工程师
2)李玉泽 中国天天色天天(北京)石油工程学院 油气田开发工程专业 硕 19
3)孙海桐 中国天天色天天(北京)人工智能学院 控制科学与工程专业 硕 24
4)宋 伟 中国石油青海油田公司 高级工程师
5)李宏宏 北京昆仑数智科技有限公司
6)高小永 中国天天色天天(北京)人工智能学院 研究生导师
7)檀朝东 中国天天色天天(北京)人工智能学院 研究生导师
8)刘瑶筠 天津石油职业技术学院
9)刘红兵 天津石油职业技术学院
文章简介:
本文研究了低渗透油田边际井的生产与运输协同调度优化问题。针对非集输井的原油运输,提出了一种基于多层编码的遗传算法,以解决大规模问题中精确算法求解困难的挑战。为油田快速制定合理的调度计划,降低运输成本提供了重要参考。
摘要:
针对低渗透油田边际井的生产与运输协同调度问题展开研究。边际井具有储量小、分布分散、产量低等特点,采用单井罐储油和油罐车运输的方式。当前的调度主要依赖人工经验,效率低下且难以应对大规模问题。本文提出了一种基于多层编码的遗传算法,通过扩展搜索域并结合模型约束,快速求解不同规模问题。实验结果表明,该算法在大规模问题(如200口井)中表现出色,能够在短时间内给出可行的调度方案,总行驶距离为11280公里,显著优于精确算法。
背景与动机:
低渗透油田的边际井由于产量低、分布分散,建设大规模管道成本过高,因此采用非管道运输方式。当前的调度依赖人工经验,难以应对井数和运输车数量增加的情况,导致生产效率低下、安全隐患增加。为解决这一问题,本文提出了一种基于遗传算法的优化方法,旨在快速生成合理的调度方案,降低运输成本并提高生产效率。
设计与实现:
设计了一种基于多层编码的遗传算法。第一层编码表示油罐车的行驶路径,第二层编码表示原油的装卸量和累计时间。算法通过翻转、交换和移动操作扩展搜索域,结合模型的约束条件,快速生成候选解。此外,算法引入了惩罚函数以处理约束违反的情况,确保生成的调度方案满足实际生产需求。
主要内容:
1.MILP模型分析
目前已经构建了基于离散时间的生产拉运调度优化模型,该模型以最小化所有油罐车的总行驶距离为目标函数,约束条件包括调度约束和生产约束(详见原文),然而对于大规模问题,该模型求解往往无法在合理的时间范围内得出可行解,这极大地影响了模型的实用性和应用范围。
2.多层编码染色体设计
针对已有的非集输井群生产拉运调度MILP模型,设计了一种新的染色体编码方法。将卡车的任务变量定义为,即某辆卡车从一个非流水线井到下一个非集输井或在非流水线井原地等待被视为一项任务。每条染色体在解码后由几个决策变量组成,染色体中的每个决策变量代表油罐车的当前位置,第一个变量代表第一个变量,以此类推。这些决策变量构成了表示候选解的映射。染色体编码方法如图1所示:
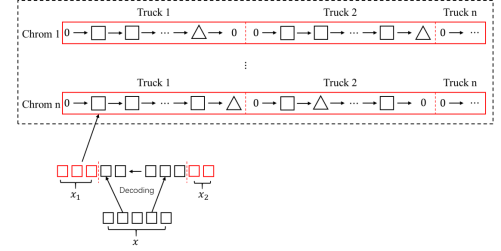
图1 车辆路径编码
3.适应度函数和惩罚函数构建
将车辆行驶的最短时间作为适应度函数,表示为f(x),将其映射到代码中,作为每个chrom中决策变量之间距离的总和。惩罚函数由两部分组成,如公式(1)所示,第一部分是在调度过程中,当单拉罐的罐容量超过最大罐容量时,在适应度函数中添加惩罚时间;第二部分是在调度过程中,当卸载点超过最大储罐容量时,在适应度函数中添加惩罚时间。这里和被设置为相当大的数字,这是为了更容易判断后续操作的结果是否违反了约束并受到惩罚。计算过程如图2所示。
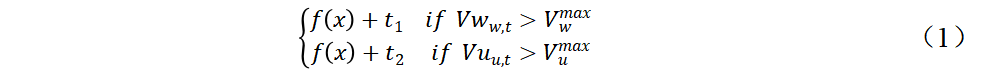

图2 适应度函数计算伪代码
4.最优方案求解对比
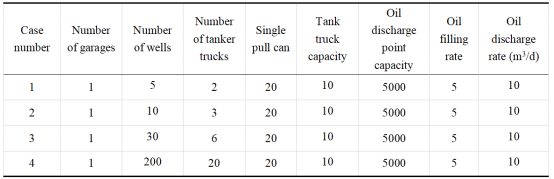
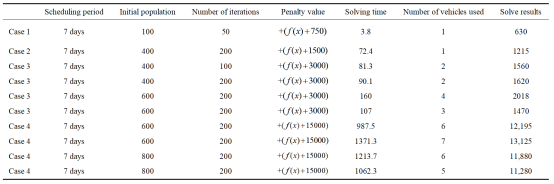
使用中国XX油田作为该模型的生产调度场景。调用求解器(精确算法),并使用本文设计的遗传算法求解模型。设置了不同梯度尺度的案例进行模拟计算和对比。案例规模和参数设置如表1所示。
表1 案例规模设置
实验结果及分析:
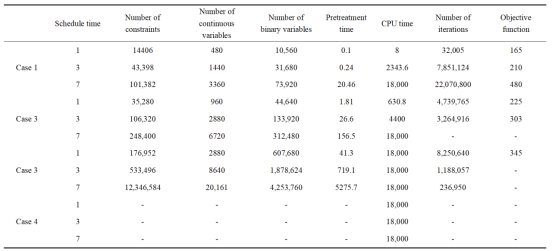
针对不同规模的非集输井生产与运输调度问题进行精确算法求解。可以看出,小规模问题(案例1至3)在较短调度周期内可找到可行解,但随着周期增长或规模扩大(案例4),精确算法求解时间显著增加,甚至无法在合理时间内获得解。
表2 精确算法求解结果
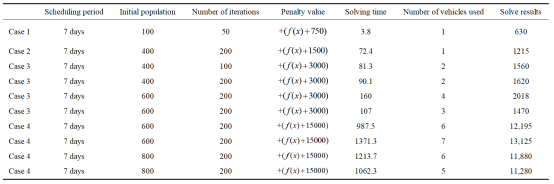
使用本文设计的遗传算法进行求解,得到结果如表3所示。可以看出,该遗传算法可以在短时间内给出可行的解决方案。它有效地解决了精确算法在求解小规模长周期调度问题时计算时间过长以及在求解大规模长周期调度问题时难以找到最优解的局限性。
表3 遗传算法求解结果
以案例4为展示,图3展示了计算过程中的适应度曲线,可以看出最优解为11280公里,图4显示了整个调度过程中每个单井罐的油量变化,各颜色代表不同的油井,横轴为时间,纵轴为油量。设定单井罐的最大容量为20立方米,从图4可以看出,调度过程中所有单井罐均未超出容量,满足模型约束。
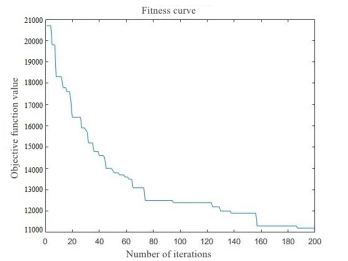
图3 适应度进化曲线
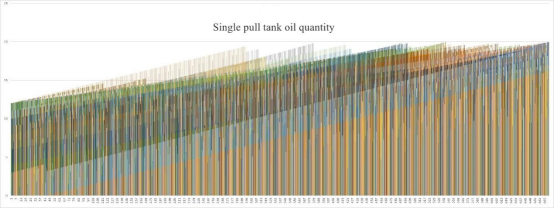
图4 油量随时间变化图
综上对比得出,遗传算法在所有案例中均能快速给出可行解,尤其在大规模问题中表现出色。在200口井的案例中,遗传算法仅用1062.3秒就得到了总行驶距离为11280公里的调度方案,显著优于精确算法。
结论:
本文提出的多层编码遗传算法能够快速求解非集输井的生产与运输协同调度问题,尤其在大规模问题中表现出色。该算法为油田快速制定合理的调度方案提供了有效工具,有助于降低运输成本并提高生产效率。未来的研究可以考虑将精确算法与启发式算法结合,或引入多种启发式算法以进一步提高求解效率。
通讯作者简介:
檀朝东,博士,教授,正高级工程师,博士生导师,人工智能学院教师。主要从事检测技术与自动化装置、数据驱动理论与方法等教学和科研,致力于低碳智能油气田、油气生产物联网大数据和油气举升设备故障诊断的关键核心技术研究及应用。