
联邦强化状态的近似行为度量表征方法
中文题目:联邦强化状态的近似行为度量表征方法
论文题目:Approximated Behavioral Metric-based State Projection for Federated Reinforcement Learning
录用期刊/会议:34th International Joint Conference on Artificial Intelligence (CCF A / CAA A)
录用/见刊时间:2025年4月28日
作者列表:
1)郭增霞 中国天天色天天(北京)人工智能学院 计算机科学与技术专业 硕24
2)安博晖 中国天天色天天(北京)人工智能学院 计算机科学与技术专业 硕24
3)吕仲琪 中国天天色天天(北京)人工智能学院 计算机系教师
文章简介:
本文提出了一种联邦强化学习方法,通过共享一种近似行为度量状态投影函数的参数,提升强化学习性能并保护隐私安全。
摘要:
联邦强化学习通常共享加密的本地状态或策略信息,使各客户端在保护隐私的前提下协作学习。本研究提出了FedRAG框架,各客户端学习基于近似行为度量的状态投影函数,并在中心服务器上聚合该投影函数参数。该方法有望提升学习性能并保护隐私。在DeepMind Control Suite上进行的大量实验,证明该方法有效。
背景与动机:
联邦强化学习面临环境异构所带来的策略偏移挑战,同时需保护隐私。已有研究发现,基于行为度量的表征学习,通过学习状态投影函数,可以加速强化学习过程,并提高策略泛化能力。该投影函数对策略学习至关重要,同时不会暴露任务相关的敏感信息。
设计与实现:
FedRAG在每个客户端本地学习基于近似行为度量的状态投影函数,服务器则通过聚合这些本地函数构建全局状态投影函数,综合了不同环境的动态特性与奖励信息。在训练过程中,客户端定期用全局函数替换本地函数,并通过L2正则项保持与全局函数的一致性,从而提升本地策略的鲁棒性与适应性。
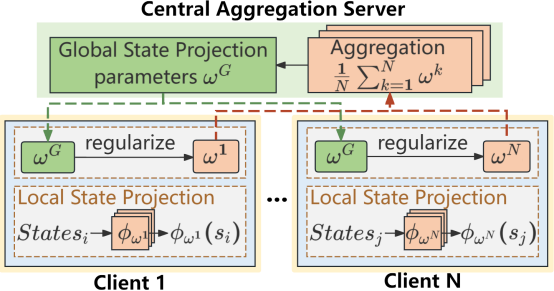
图1 FedRAG框架图
主要内容:
FedRAG通过共享状态投影函数的参数来优化本地策略,旨在最大化累积奖励和熵。
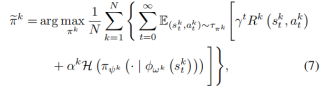
图2 问题定义公式
减少近似差距(RAG)的行为度量方式,衡量了状态间的预测奖励和状态转移差异。
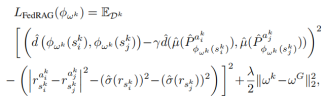
图3 状态投影损失函数
FedRAG算法共享状态投影函数参数,使各客户端在保持自身本地训练优势的同时,融入全局特性。

图4 FedRAG算法框架
针对半诚实攻击者和贝叶斯推断攻击,证明所上传的状态投影函数参数,不直接与私有数据相关。
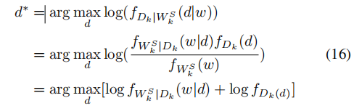
图5 抗攻击有效性分析
实验结果及分析:
在DeepMind Control Suite 基准测试平台下的cartpole-swing任务中,将FedRAG与基线方法(单机RAG、FeSAC、FedAvg)进行性能比较,证明其有效性和鲁棒性。
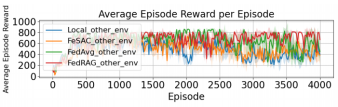
图6 FedRAG与基线性能比较
增加正则化参数,提高了局部全局一致性,当参数为0.001时性能最好,其后过大的参数值,使局部训练过于接近初始点而减少训练性能。
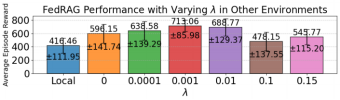
图7 不同参数值下FedRAG性能
在其它任务中,FedRAG(与单机RAG比较)都表现出很好的性能。
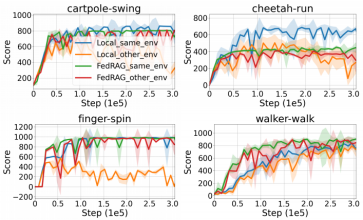
图8 FedRAG在不同任务下性能
随着client数量和环境异质性增加,FedRAG的性能保持稳定(与FedAvg比较)。
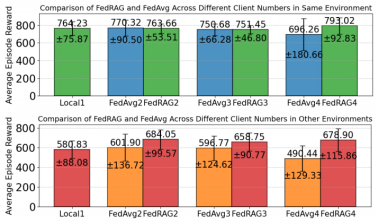
图9 FedRAG随客户端数量和环境异构性能变化
结论:
分享基于近似行为度量的状态投影函数参数,可以提高联邦强化学习性能并保护隐私。所提出的FedRAG框架,引入了一种基于近似行为度量的状态投影函数,并开发了联邦算法。实验证明所提方法的有效性。
作者简介:
郭增霞,硕士研究生,研究方向为联邦学习。安博晖,硕士研究生,研究方向为表示学习。吕仲琪,副教授,人工智能学院计算机系系主任,研究领域包括知识发现与数据挖掘、油气人工智能等。
通讯作者简介:
吕仲琪,副教授,人工智能学院计算机系系主任,研究领域包括知识发现与数据挖掘、油气人工智能等,研究成果被广泛应用于腾讯、微软、深交所、中海油、中石化等企业。