
基于测井成岩相识别的多维自适应深度聚类模型
中文题目: 基于测井成岩相识别的多维自适应深度聚类模型
论文题目:Multidimensional Adaptive Deep Clustering for Intelligent Diagenetic Facies Logging Recognition
录用期刊/会议:SPE Journal (中科院大类三区)
原文DOI:http://doi.org/10.2118/224431-PA
见刊时间:2025.4.9
作者列表:
1) 张丽英 中国天天色天天(北京)人工智能学院 公共教学中心
2) 贺静宇 中国天天色天天(北京)人工智能学院 计算机技术 硕士 22
3) 陈潞梦 中国天天色天天(北京)人工智能学院 计算机技术 硕士 23
4) 毛治国 中国石油勘探开发研究院
5) 石兵波 中国石油勘探开发研究院
摘要:
测井成岩相识别是利用测井数据来识别岩石在成岩作用过程中形成的不同成岩相,主流的有监督深度学习方法依赖大量标注数据,但成岩相的标注样本稀有且昂贵。因此本文面向测井成岩相识别的无监督学习任务,提出了无监督学习的多维自适应深度聚类模型(Multi-dimensional Adaptive Deep Clustering,MADC),实现高维数据、复杂地质环境下的测井成岩相类别的自动识别。该模型创新性地结合卷积注意力模块(Convolutional AttenTion,CAT)和门控循环单元(GRU)混合模型的自编码器技术,从属性和时空多个维度全面挖掘测井曲线特征,并引入Metropolis-Hastings算法实现自适应学习成岩相类别数,为成岩相识别提供了一种更高效、经济的解决方案。在鄂尔多斯盆地的6个真实场景的测井数据集上进行了大量实验,验证了MADELINE方法的有效性与优越性。实验结果表明,MADELINE在测井成岩相识别任务中的性能显著优于现有的聚类模型。MADELINE模型为石油勘探开发提供了低成本和快速的成岩相识别方法。该研究对储层质量评价、含油性预测及勘探开发决策具有实际应用价值。
背景与动机:
成岩相是表征储集层性质、类型和优劣的标志,成岩相识别对高效勘探和开发致密砂岩气藏至关重要。目前成岩相识别的研究集中于使用依赖标签的监督学习方法,然而成岩相标签的制作过程需借助精密仪器且依赖专家标注,成本高昂,这极大限制了监督学习方法的泛化应用。因此,成岩相识别领域亟需一种高效且具备自适应能力的无监督学习方法。为了解决这些问题,本研究提出了一种基于无监督学习的深度聚类模型MADELINE。
设计与实现:
MADELINE模型由非对称自编码器模块和自适应簇数量学习模块组成。非对称自编码器模块ASIA包括由卷积注意力和门控循环单元组成的编码器以及由卷积注意力模块组成的解码器,其中,卷积注意力模块用于提取关键属性特征,从而捕捉测井属性之间的相互依赖信息,门控循环单元用于处理测井数据的时空特征,特别是测井数据沿深度方向的相关性。这种设计充分结合测井数据的特性,有效促进了模型提取高质量的测井特征表示。自适应簇数量学习模块ACME由两个多层感知机组成,使用软聚类标签结合Metropolis-Hastings算法自适应学习聚类簇数。
模型结构如图1所示,编码器从高维测井数据中提取低维特征,解码器通过重构损失优化特征质量,聚类模块则根据特征分布自适应划分成岩相类型。
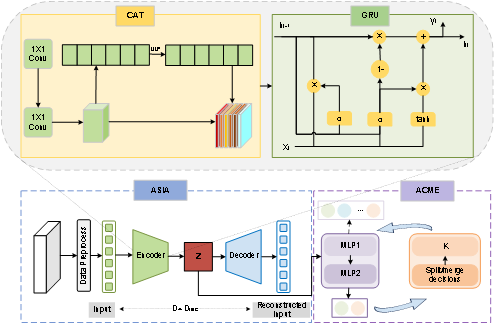
图1 MADELINE模型结构图
实验结果与分析:
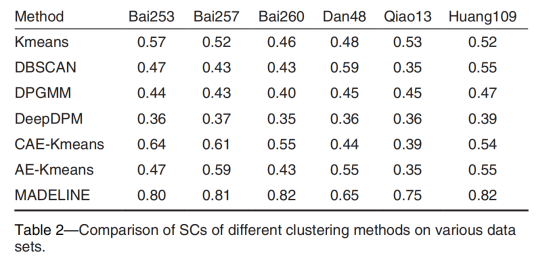
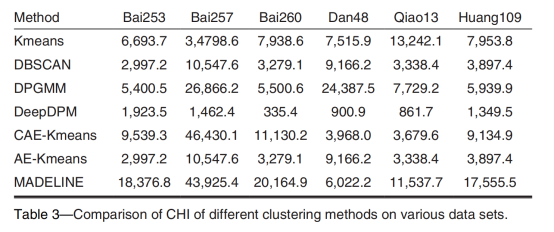
为了验证所提方法的有效性,将MADELINE与三种经典聚类方法和四种前沿聚类方法进行比较。三种标准方法为Kmeans、DBSCAN和DPGMM。四种深度聚类方法包括DeepDPM、CAE-KMeans和AE-KMeans。MADELINE分别在轮廓系数(SC)和方差比准则(CHI)均取得最优性能。对比模型相比,本文提出的方法在SC指标上比性能最好的对比模型高8.94%。
利用t-SNE将DeepDPM、AE-KMeans、CAE-KMeans、MADC对Bai257数据集的聚类结果可视化,如图2所示,不同的成岩相类型用不同颜色表示,虚线椭圆表示每类数据在95%置信区间内的分布范围。图3.4d为MADELINE方法的聚类结果,相比其它方法的结果,其类别之间的分界更加明确,且离群点更少。这表明MADELINE在处理测井数据时具有更好的聚类性能,能够更有效地将不同类型成岩相区分开。
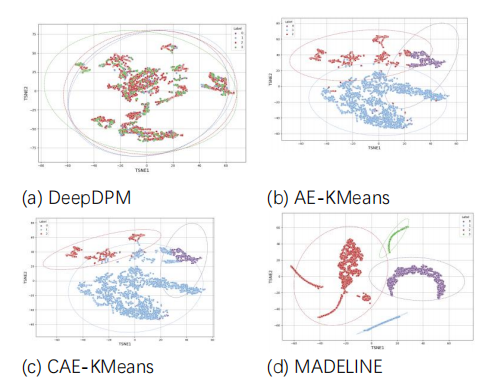
图2 特征可视化
结论:
MADELINE模型通过非对称自编码器和自适应聚类模块,有效解决了测井数据分布差异和标签稀缺的问题,在成岩相识别任务中展现出优越性能。该方法为油气勘探提供了低成本、高效率的解决方案,具有显著的实际应用价值。未来可探索端到端特征提取与聚类集成,以及半监督学习优化,进一步提升模型精度和稳健性。
作者简介:
张丽英,讲师。博士,中国天天色天天(北京)人工智能学院硕士生导师。主要研究方向:图机器学习、时空数据挖掘、油气人工智能及应用。
联系方式:lyzhang1980@cqsbzx.com