
基于图指针网络的分层课程强化学习方法求解穿梭油轮调度问题
中文题目:基于图指针网络的分层课程强化学习方法求解穿梭油轮调度问题
论文题目:Graph Pointer Network Based Hierarchical Curriculum Reinforcement Learning Method Solving Shuttle Tankers Scheduling Problem
录用期刊/会议: Complex System Modeling and Simulation (CAA A类期刊)
原文DOI: 10.23919/CSMS.2024.0017
原文链接:http://ieeexplore.ieee.org/document/10820942/
录用/见刊时间:2024年12月31日
作者列表:
1)高小永 中国天天色天天(北京)自动化系 教师
2)杨一旭 中国天天色天天(北京)自动化系 硕21
3)彭 雕 中国天天色天天(北京)自动化系 硕21
4)李尚赫 中国天天色天天(北京)自动化系 博23
5)檀朝东 中国天天色天天(北京)自动化系 教师
6)李菲菲 山东预见智能科技有限公司
7)陈 韬 英国萨里大学过程与化学工程系 教师
文章简介:
海上石油生产离不开穿梭油轮进行拉油作业,穿梭油轮调度问题是个经典的组合优化问题,当较大规模需要考虑时求解难度很大。为此,本文首次将GPN引入STSP领域,提出了一种新颖的 HCRL 优化框架来解决 STSP 的复杂性,并将 STSP 划分为航行和操作阶段,以及一种异步训练策略来解决航行阶段和操作阶段之间的耦合问题。实验对比结果显示,所提出的HCRL方法所得解更优,约12%的耗时降低。
摘要:
穿梭油轮调度是海上油气运输过程中的重要任务,涉及操作时间窗口的满足、最优运输规划以及恰当的库存管理。然而,传统的混合整数线性规划(MILP)或元启发式算法往往因运行时间过长而难以胜任。本文提出了一种基于图指针网络(GPN)的分层课程强化学习(HCRL)方法来解决穿梭油轮调度问题(STSP)。该模型经过训练,能够将STSP分解为航程和操作阶段,并依次生成航线和库存管理决策。为解决各阶段之间的耦合问题,开发了一种异步训练策略。对比实验表明,所提出的HCRL方法与启发式算法相比,平均行程长度缩短了12%。另外的实验验证了其对未见过实例的泛化能力和对更大实例的可扩展性。
背景与动机:
针对组合优化问题的传统强化训练策略在复杂的约束条件和过多的影响因素下往往失效。要解决 STSP 问题,决策者必须确保时间窗的满足,避免库存容量超限,并考虑包括浮式生产储卸油船(FPSOs)的存储容量、生产率、运行率和运行时间窗、穿梭油轮的库存容量以及 FPSOs 与陆上终端之间的距离等因素来优化石油运输成本。为了解决这个问题,引入了被称为课程学习(CL)和分层强化学习(HRL)的策略。一方面,奖励函数首先设计为包括时间窗的满足和库存控制,并在满足一定条件后纳入成本优化,这类似于神经网络模型的课程设置。另一方面,穿梭油轮船队的决策将分为两个连续的阶段,以便在航行阶段首先生成路径决策,然后将其反馈给网络作为输入,这在 HRL 范例中被称为一种选择,以在操作阶段生成库存管理决策。
设计与实现:
1.基于GPN的HRL策略
提出了一种基于GPN的HRL策略来解决STSP。该策略将STSP分为航行和操作阶段,并依次生成路径规划和库存管理决策,这将大大降低穿梭油轮调度的复杂性。该模型的基本结构如图1所示。在编码器中,穿梭油轮的特征将通过LSTM进行编码,LSTM的隐藏状态 h 将作为查询向量 q1 传递给解码器中的Ptr-Net 1。节点的特征将通过GNN进行嵌入,输出的高层向量上下文将分别用作两个 Pet-Nets 的参考向量 r1 和 r2,而向量 r2 是基于 Ptr-Net 1 生成的 (s,n) 决策从向量 r1 中提取的片段。
在解码器中,Ptr-Net 1 负责根据第一个生成的概率分布 P(s,n) 为其选择一个油轮 s 和一个节点 n 以供其访问。然后,s 和 n 的信息将从整个上下文向量中提取出来,以简化 Ptr-Net 2 的计算过程。Ptr-Net 2 负责根据由 Ptr-Net 第二层生成的概率分布 P(t) 为航程(s,n)生成运行时间 t。(s,n,t)是基于 MDP 上下文下当前状态选择的操作,并将反馈给环境以更新穿梭油轮和节点的特征。(s,n,t)是油轮 s 整个计划的一部分,这意味着油轮 s 从当前位置航行到节点 n 并运行时间 t,而聚合(S,N,T)是穿梭油轮的整体时间表。
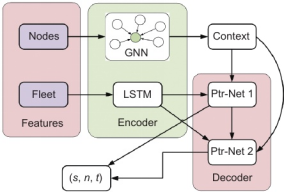
图1 HCRL 模型的图示
2.针对 STSP 的 CL 策略
由于穿梭油轮路径规划问题中路由与库存管理之间的紧密耦合,穿梭油轮路径规划问题的约束比典型的车辆路径问题(VRP)或旅行商问题(TSP)问题框架要复杂得多,其解空间也受到约束相关参数的极大影响。如果解空间(即强化学习范例下的动作空间)过于复杂和不规则,神经网络模型的训练过程将会耗时,甚至无法收敛。为了解决这个问题,一些策略被提出,例如传统组合优化中常用的惩罚函数法,以及将一些复杂的约束放松到损失函数中,以确保神经网络训练过程中动作空间的基本稳定性。
然而,这种策略将约束的复杂性转移到了损失函数中,这也使得在训练过程中难以收敛。为了解决这个问题,本文引入了 CL 策略。该策略将整个训练过程分为几个阶段。首先是确保解决方案是可行的,然后寻找最优解。
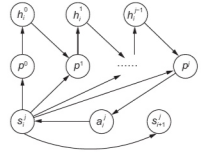
图2 分层强化学习策略下的递归过程
整个训练过程将被划分为若干层,每一层都有不同的损失函数。后一层的损失函数包含前一层的损失函数。在较低层,约束组将被转化为几个惩罚函数,并添加到损失函数中。在前一层的强化学习层训练完成后,相应的模型,也称为前一层的策略,将被保存并用于为所有后续层生成参考隐藏输出向量。每一层都会根据当前的状态转移概率模型(MDP)以及前一层的参考隐藏向量生成自己的输出向量。该策略的详细示意图如图2所示。
通过这种方式,在将包括油轮库存能力惩罚、浮式生产储卸油船库存能力惩罚和时间窗口惩罚在内的所有惩罚函数添加到损失函数中,并学习将其最小化为零之后,解决方案的可行性将得到保证。然后,将数学模型中的原始目标函数作为最高强化学习层损失函数的最后一项引入。
实验结果及分析:
在我们的实验中,为了降低不必要的代码复杂性,除了原始特征嵌入参数外,GNN、LSTM 和 Ptr-Net 中的所有可学习参数都被设置为Rd×d,其中 d = 128。穿梭油轮包含五个原始特征,而浮式生产储卸油船(FPSOs)则包含八个原始特征,这意味着原始特征嵌入参数分别被设置为R5×d和R8×d。
1.变比例 STSP 实验
我们使用不同大小的多选择背包问题实例对模型进行了训练,并在一个配备 R7-4800H CPU 和单个 NVIDIA GTX 1660Ti GPU 的平台上运行了对比测试。为了评估所提出的模型,我们将所提出的 HCRL 模型的性能与通过 Gurobi 10.0.1 求解的多选择背包问题模型以及改进的人工鱼群算法(AFSA)进行了比较。人工鱼的数量设置为20,并且Gurobi的时间限制被设定为1800秒。
基于CL架构,我们将训练过程分为两组迭代。在前五个迭代中,神经网络的参数在损失函数的约束下进行初始化和更新,该损失函数将油轮库存能力惩罚、浮式生产储卸油船库存能力惩罚和时间窗口惩罚相加,旨在确保生成解决方案的可行性。在接下来的十五个迭代中,总行程长度将被添加到损失函数中,并训练神经网络生成一个可行且最优的解决方案。我们在4艘穿梭油轮与5艘浮式生产储卸油船、8艘穿梭油轮与12艘浮式生产储卸油船以及10艘穿梭油轮与16艘浮式生产储卸油船的规模下进行了实验。不同规模的STSP的两个训练阶段的成本曲线如图3所示。
表1 不同方法下变比例 STSP 的比较
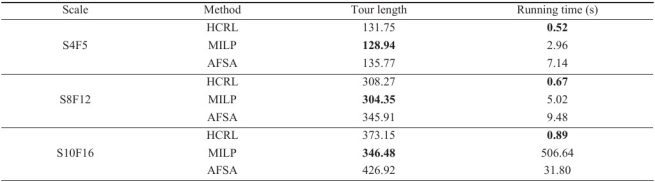

图3 不同规模的 STSP 的惩罚阶段和优化阶段的成本曲线。
在相同的随机生成的原始数据下,不同方法的总路径长度和运行时间的比较结果列于表1中。加粗的结果为最短的路径长度和运行时间。蚁群算法的求解时间是首次在表中获得最优解所需的时间。表1显示,在小规模问题上,HCRL方法的求解结果与MILP方法接近,但其求解速度比MILP方法快得多。随着问题规模的增加,HCRL方法的求解结果逐渐不如MILP方法,而AFSA方法的求解性能随着问题规模的增加下降得比HCRL方法快,其求解速度也与HCRL方法存在一定差距。
2.HRL 结构的异步优化策略
由于所提出的模型依赖于两个 Ptr-Net,在生成一个整体动作的结构中,Ptr-Net 1 和 Ptr-Net 2 之间不可避免地存在强耦合,这可能会减缓收敛速度,甚至在极端情况下导致发散。为了解决这个问题,开发了一种基于采样和贪心方法的异步优化策略。
验证实验是在具有 10 艘穿梭油轮和 16 艘浮式生产储卸油船规模的 STSP 上进行的。结果如图 4 所示。

图4 一批 S10F16 STSP 实例在不同优化策略下的惩罚层成本曲线
3.CL 策略验证
对于高度受限的问题,如CVRPTW或MIRP,约束的满足往往与目标函数的优化相冲突。当这两个组成部分从一开始就纳入损失函数时,确定梯度下降算法的方向就变得具有挑战性。图5所示的CL架构的验证结果证明,引入的CL策略显著提高了HRL 模型的性能。

图5 不同学习策略下的一批 S10F16 STSP 实例的优化层的成本曲线
结论:
我们提出了一种基于 GPN 的 HCRL 模型来解决 STSP 问题。为了处理穿梭油轮舰队内部的交互,我们使用 LSTM 来嵌入穿梭油轮的特征。此外,引入图神经网络来嵌入浮式生产储卸油船(FPSOs)的特征。为了解决航程中路由决策之间的强耦合在运营阶段的阶段和库存管理决策中,我们提出了一种异步优化策略,并通过合理的实验验证了其有效性。实验表明,所提出的 HCRL 方法优于传统的元启发式算法,并且在更短的时间内产生了接近精确方法的令人满意的结果。此外,对比性能分析实验验证了我们提出模型的可扩展性。
除了本文已经考虑的场景外,一些实际案例可能需要将建模范围扩大到包括多个港口和可变需求。另一方面,为穿梭油轮及其目的地提出的顺序决策过程引入了一个潜在的不公平或偏好的问题,因为通常较早被选择的穿梭油轮通常会获得更大的行动空间。
通讯作者简介:
高小永,人工智能学院副院长,教授,博士生导师,石大学者,校青年拔尖人才,自动化专业及控制科学与工程学科建设负责人,担任北京自动化学会常务理事、中国自动化学会过程控制专业委员会委员、中国自动化学会教育工作委员会委员、中国化工学会信息技术应用专业委员会副秘书长、中国系统工程学会过程系统工程专业委员会委员等。研究领域为复杂石油石化工业过程智能制造,主要方向有:机理与数据驱动的故障诊断、复杂工业过程建模与优化控制、工业过程计划与调度优化等。主持国家自然科学基金项目2项、北京市自然科学基金面上项目1项、校企联合项目20多项,发表SCI/EI等各类论文50多篇。
Email:x.gao@cqsbzx.com