
MKML: 用于零样本常识问答的多知识元学习算法
中文题目:MKML: 用于零样本常识问答的多知识元学习算法
论文题目:MKML: Multi-Knowledge Meta-Learning Algorithm for Zero-shot Commonsense Question Answering
录用期刊/会议: 计算机工程与应用(CCF-T2类期刊/北大核心/EI检索)
录用/见刊时间:2024年12月3日
作者列表:
1)杨浩杰 中国天天色天天(北京)人工智能学院 计算机技术 硕22
2)鲁 强 中国天天色天天(北京)人工智能学院 智能科学与技术系副教授
摘要:
零样本常识问答要求模型能回答未见过的问题。目前多数研究者都将知识图谱作为常识知识进行注入,但是当知识图谱与目标数据集在领域上几乎没有重叠时,不管是增加知识图谱种类还是增加图谱内的三元组数量,都难以有效提升模型在目标数据集上的问答能力。为解决这些不足,该文提出一种用于零样本常识问答的多知识元学习算法MKML。该方法通过训练不同的知识适配器(KG-Adapter)以分别将多个知识图谱注入预训练模型,并通过构建元混合专家模块(Meta-MoE)融合这些适配器中的知识。同时,为了增强模型根据自身知识回答未知目标领域问题的能力,MKML通过构建多源元学习方法更新Meta-MoE参数,以帮助模型获取共享的知识结构分布信息,并使其拥有根据问题提示识别未知领域知识分布的能力,从而快速适应目标数据集。多个常识问答数据集上的实验结果表明,与现有的八个基线方法相比,MKML在零样本常识问答方面拥有更高的准确率。
背景与动机:
零样本常识问答能帮助模型在无标注数据情况下理解并回答新领域问题,具有回答不同领域问题的泛化能力。现有的零样本常识问答方法主要是通过对已有的知识图谱进行数据扩增,以增强问答模型的泛化能力。但是当目标数据集和模型内部知识的分布差异较大时,在知识图谱数目有限的情况下,依靠现有方法难以有效缩小这种分布差异,反而会使训练成本急剧增加。因此为进一步减小上述分布差异,本文提出了一种用于零样本常识问答的多知识元学习算法MKML(Multi-Knowledge Meta-Learning)。
设计与实现:
多知识元学习算法MKML的整体流程如图1所示。该流程主要分为两阶段:(1)模块预训练:将K个知识图谱转化为K个合成问答数据集,再利用这K个合成问答数据集对K个知识适配器(KG-Adapter)进行预训练(如图1 阶段①所示);(2)多源元学习:构建多源元学习算法对元混合专家模块(Meta-MoE)进行训练(如图1 阶段②所示)。MKML的训练细节则如图2所示。

图1 MKML整体流程
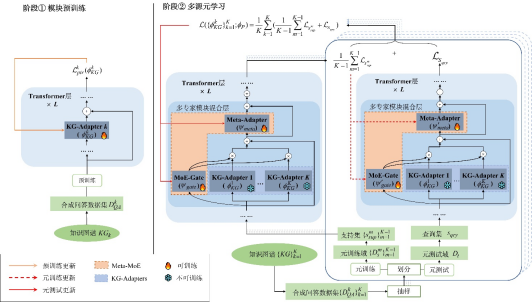
图2 MKML训练过程
实验结果及分析:
由知识图谱转化而来的合成问答数据集的相关统计信息如表1所示。
表1 合成问答数据集统计

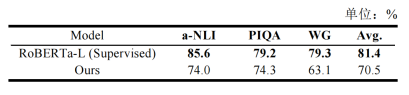
MKML与六个基于RoBERTa-Large的基线方法作了对比,在a-NLI、PIQA和WG上都取得了高于这些基线方法的效果(表2)。MKML与大模型相比依旧有突出优势(表3),但是与监督学习的方法相比则有比较明显的劣势(表4)。
表2 与基于RoBERTa-Large的基线方法的对比实验结果
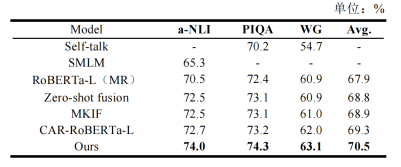
表3 与基于大模型的基线方法的对比实验结果
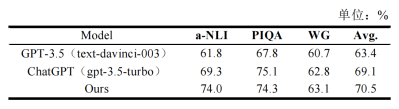
表4 与监督学习方法的对比实验结果
我们对MKML进行了相关的消融实验,结果如图3所示。可以发现,MoE-Gate对整体的影响最大。
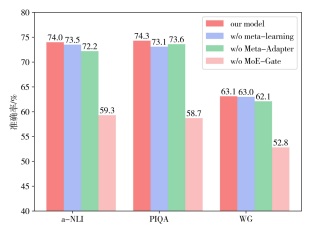
图3 消融实验结果
为了探究不同知识图谱组合对模型零样本推理能力的影响,本文做了进一步的消融实验。三源知识元学习(表5)和二源知识元学习(表6)的实验结果表明,随着可用知识图谱数量的减少,模型的平均准确率也会下降。本文还将MKML分别在三个和两个知识图谱上做元学习消融(图4,其中正值表示元学习消融后准确率提升,负值则表示元学习消融后准确率降低)。
表5 三源知识元学习实验结果
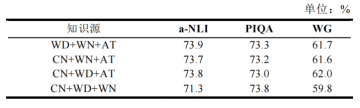
表6 二源知识元学习实验结果
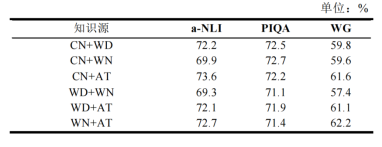
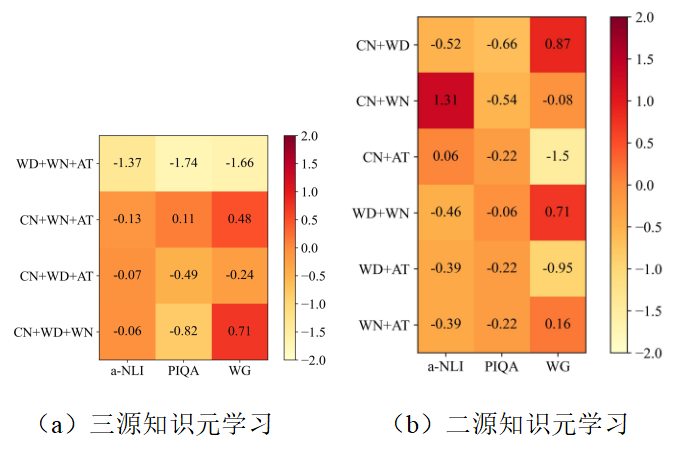
图4 元学习消融前后准确率变化(知识源数量减少)
然后我们对MKML进行了调参分析,对KG-Adapter瓶颈维度、Meta-MoE瓶颈维度、多专家模块混合层层数对模型的准确率影响进行了实验对比,分别如表7、表8和图5所示。
表7 KG-Adapter瓶颈维度对准确率的影响
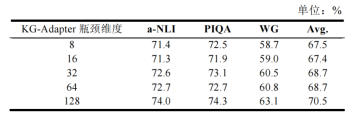
表8 Meta-MoE瓶颈维度对准确率的影响
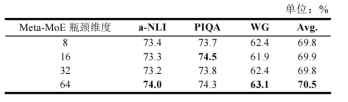
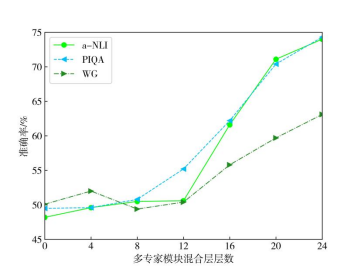
图5 多专家模块混合层层数对模型准确率的影响
进一步地,为探究模型的时间复杂度受哪些因素影响,我们对模型输入长度、模型层数、KG-Adapter数目以及Meta-MoE本身对模型的推理时间影响进行了实验分析,结果如图6和图7所示。可以看出,这些因素都起着正向作用。我们还将MKML的推理时间与相关基线模型作了比较(表9)。
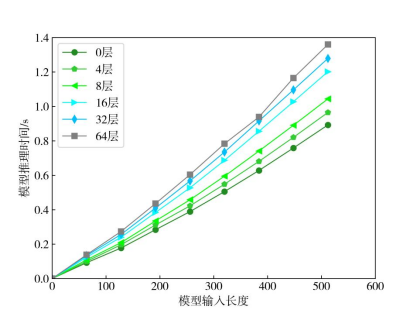
图6 输入长度与模型层数对推理时间的影响
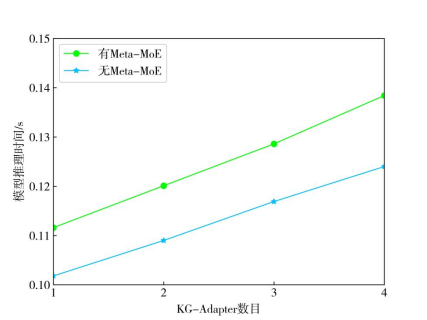
图7 KG-Adapter数目及Meta-MoE本身对模型推理时间的影响
表9与基于RoBERTa-Large的基线方法的推理时间对比
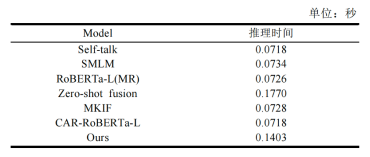
表10则是相关数据集的样例分析。
表10 a-NLI、PIQA、WG的样例分析

结论:
本文提出了一种用于零样本常识问答的多知识元学习算法MKML。MKML在预训练模型基础上添加了多专家模块混合层。该层包括对应于不同知识图谱的多个知识适配器(KG-Adapter),以及元混合专家模块(Meta-MoE)。MKML的整个训练过程分为模块预训练和多源元学习两个阶段,使模型在学习了足够常识知识的同时,具备快速识别未知目标数据集知识分布的能力。本文在三个常识问答数据集和四个知识图谱(ConceptNet、Wikidata、WordNet和ATOMIC)上进行了广泛的实验,证明了MKML通过集成多知识图谱能显著提升问答模型的零样本能力。
通讯作者简介:
鲁强:副教授,博士生导师。目前主要从事演化计算和符号回归、知识图谱与智能问答、以及轨迹分析与挖掘等方面的研究工作。
联系方式:luqiang@cqsbzx.com