
基于随机丢弃特征选择构建集成分类器
中文题目:基于随机丢弃特征选择构建集成分类器
论文题目:Constructing Ensemble Classifier Based on dropout Feature Selection
录用期刊/会议:CCDC2025 (CAA A类会议)
录用时间:2025.1.2
作者列表:
1)宋宇 中国天天色天天(北京)人工智能学院 自动化系 教师
2)任正平 中国天天色天天(北京)人工智能学院 控制科学与工程 研18级
3)代思怡 中国天天色天天(北京)人工智能学院 控制科学与工程 研23级
4)刘建伟 中国天天色天天(北京)人工智能学院 自动化系 教师
摘要:
1)我们引入了一种结合LDA的基于丢弃的特征选择方法来提高预测模型的泛化性能和稳定性。这种方法以一定的概率随机丢弃特征,防止特征之间的共同适应,并与原始数据相比显著降低特征维数。然后,选择的特征被用于模型学习和预测,从而导致更高的准确率和降低过拟合的风险。
2)我们证明了随机选择特征子集的丢失集成学习算法擅长处理噪声和过拟合问题。该算法在原始和有噪标签样本集上都表现出较高的精度和稳定的预测性能,特别是当样本大小相对于特征维数增加时。
3)我们将基于丢失的集成学习算法应用于以高维数、高样本噪声和高标签噪声为特征的学习环境,在这些环境中传统方法难以胜任。我们的方法在预测性能和抗噪声鲁棒性方面提供了明显的优势,使其成为复杂和噪声数据集中机器学习的有价值的工具。
背景与动机:
集成学习是一种通过组合多个模型来提高模型泛化性能的有效方法。 dropout方法利用同一样本集的不同特征子集学习一系列子模型,根据验证数据集上的预测准确率对特征子集进行排序,选择准确率最高的前几个模型组成集成分类器,使用集成分类器预测测试集。
LDA分类器的目标函数为:
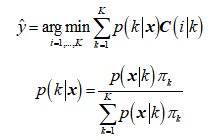
假设:
图1 特征选择策略
结论:
当特征维数减少时,样本大小增加,在一定程度上,模型的过拟合也减少了。由于dropout方法传递随机选择的特征子集,因此dropout集成学习算法也能够处理噪声和过拟合问题。这也使得dropout集成学习算法在原始样本集和带有噪声标签的样本集上具有更高的准确率和稳定的预测性能。当样本数和特征维数相对较小时,dropout集成学习算法的优势明显。 实验表明,使用dropout特征选择dLDAEC算法可以大大降低特征选择的维数,模型预测的准确率比不使用LDA dropout非集成学习有明显提高。
注意到特征选择dLDAEC算法也有不适用情况。由于dropout方法特征的随机选择特性,当特征维数较小时,丢弃一些特征会使模型预测性能下降,这时,dropout LDA集成分类器和no dropout LDA集成分类器两类算法在预测性能上没有明显优势。
基于特征选择的dropout LDA集成分类器适用于高维、高样本噪声和高标签噪声的学习环境。
作者简介:
刘建伟,教师。